0%
记一次在vue中使用axios,参数没有序列化
背景
开始用vue写项目,可是用axios进行get操作没问题,进行post操作时,post的值始终没有传过来
直到搜索到“qs序列化”关键词,才发现其中的缘由
参考
Kouss博客 http://kouss.com/3884.html
内容
设置了headers中Content-Type为application/x-www-form-urlencoded数据格式,post发起的请求仍为json类型,并没有序列化。
郁闷的是用JSON.stringify无效。

这个Form Data后台取不到数据,正常的Form Data数据应该是key:val
最终解决方法:使用qs
1 | var qs = require('qs') |
ab性能测试
背景
早先在CPK项目时,因为有用户反应页面打不开,后来采用了CDN和静态页,那段时间也用ab测试工具测试过速度,但用了之后就没深入了解(主要是没写笔记做记录,忘记了)
之后因为离职去应聘时,一个面试官问过ab测试,且对我当时的一个开源项目进行了简单的压力测试。因为采用了pjax,没用静态页,首页的测试并不理想,之后打算着将TP的静态页部分改进下,满足pjax时也能调用。
在laravel,TP5,YII2等框架性能据说都有不错的提升时,自己用TP3.2开源的项目就显得十分的老旧。如何对比速度上的差异,也就只能先记录下TP3.2时的速度,用新框架的速度来进行对比。
参考地址
作者:橙子酱
链接:http://www.jianshu.com/p/43d04d8baaf7
來源:简书
关于压力测试的概念
吞吐率(Requests per second)
概念:服务器并发处理能力的量化描述,单位是reqs/s,指的是某个并发用户数下单位时间内处理的请求数。某个并发用户数下单位时间内能处理的最大请求数,称之为最大吞吐率。
计算公式:总请求数 / 处理完成这些请求数所花费的时间,即
1 | Request per second = Complete requests / Time taken for tests |
以100并发 100次请求,各大网站的对比(20171025)
1 | 百度(www.baidu.com) 80~88 |
并发连接数(The number of concurrent connections)
概念:某个时刻服务器所接受的请求数目,简单的讲,就是一个会话。
并发用户数(The number of concurrent users,Concurrency Level)
概念:要注意区分这个概念和并发连接数之间的区别,一个用户可能同时会产生多个会话,也即连接数。
用户平均请求等待时间(Time per request)
计算公式:处理完成所有请求数所花费的时间/ (总请求数 / 并发用户数),即
1 | Time per request = Time taken for tests /( Complete requests / Concurrency Level) |
服务器平均请求等待时间(Time per request: across all concurrent requests)
计算公式:处理完成所有请求数所花费的时间 / 总请求数,即
1 | Time taken for / testsComplete requests |
可以看到,它是吞吐率的倒数。
同时,它也 等于 用户平均请求等待时间/并发用户数,即
1 | Time per request / Concurrency Level |
1 | 百度(www.baidu.com) 1100~1300 11.00~13.00 |
单次测试结果的说明
1 | Concurrency Level: 100 //并发请求数 |
关于登录的问题
有时候进行压力测试需要用户登录,怎么办?
请参考以下步骤:
1 | 先用账户和密码登录后,用开发者工具找到标识这个会话的Cookie值(Session ID)记下来 |
1 | 如果只用到一个Cookie,那么只需键入命令: |
1 | 如果需要多个Cookie,就直接设Header: |
如何防止别人用ab之类的测试软件恶意请求自己的网站
网友回答:
1 | 目前此类软件可以很真实的模拟浏览器请求,所以在少量的请求下,基本上是屏蔽不了的。 |
1 | nginx的话可以用HttpLimitReqModule |
mysql中的视图(转)
背景
上一个项目接手后,在转移数据庫的时候,数据庫的转移失败,那是我第一次接触mysql视图。但是那时没去研究啥是视图。
今天查看另一个项目时,又发现了mysql视图的存在,需要充电一下了!
文章来源
作者:风一样的码农
原文地址:http://www.cnblogs.com/chenpi/p/5133648.html
什么是视图
通俗的讲,视图就是一条SELECT语句执行后返回的结果集。所以我们在创建视图的时候,主要的工作就落在创建这条SQL查询语句上。
视图的特性
视图是对若干张基本表的引用,一张虚表,查询语句执行的结果,不存储具体的数据(基本表数据发生了改变,视图也会跟着改变);
可以跟基本表一样,进行增删改查操作(ps:增删改操作有条件限制);
视图的作用
方便操作,特别是查询操作,减少复杂的SQL语句,增强可读性;
更加安全,数据库授权命令不能限定到特定行和特定列,但是通过合理创建视图,可以把权限限定到行列级别;
使用场合
权限控制的时候,不希望用户访问表中某些含敏感信息的列,比如salary…
关键信息来源于多个复杂关联表,可以创建视图提取我们需要的信息,简化操作;
视图实例1-创建视图及查询数据操作
现有三张表:用户(user)、课程(course)、用户课程中间表(user_course),表结构及数据如下:
表定义:
1 | -- ---------------------------- |
这时,当我们想要查询小张上的所以课程相关信息的时候,需要这样写一条长长的SQL语句,如下:
1 | SELECT |
但是我们可以通过视图简化操作,例如我们创建视图view_user_course如下:
1 | -- ---------------------------- |
几点说明(MySQL中的视图在标准SQL的基础之上做了扩展):
ALGORITHM=UNDEFINED:指定视图的处理算法;
DEFINER=root@localhost:指定视图创建者;
SQL SECURITY DEFINER:指定视图查询数据时的安全验证方式;
创建好视图之后,我们可以直接用以下SQL语句在视图上查询小张上的所以课程相关信息,同样可以得到所需结果:
1 | SELECT |
视图实例2-增删改数据操作
继续,我们可以尝试在视图view_user_course上做增删改数据操作,如下:
1 | update view_user_course set username='test',coursename='JAVASCRIPT' where id=3 |
遗憾的是操作失败,提示错误信息如下:
[SQL] update view_user_course set username=’test’,coursename=’JAVASCRIPT’ where id=3
[Err] 1393 - Can not modify more than one base table through a join view ‘demo.view_user_course’
因为不能在一张由多张关联表连接而成的视图上做同时修改两张表的操作;
那么哪些操作可以在视图上进行呢?
视图与表是一对一关系情况:如果没有其它约束(如视图中没有的字段,在基本表中是必填字段情况),是可以进行增删改数据操作;
如我们创建用户关键信息视图view_user_keyinfo,如下:
1 | -- ---------------------------- |
进行增删改操作如下,操作成功(注意user表中的其它字段要允许为空,否则操作失败):
1 | INSERT INTO view_user_keyinfo (account, username) |
1 | DELETE |
1 | UPDATE view_user_keyinfo |
视图与表是一对多关系情况:如果只修改一张表的数据,且没有其它约束(如视图中没有的字段,在基本表中是必填字段情况),是可以进行改数据操作,如以下语句,操作成功;
1 | update view_user_course set coursename='JAVA' where id=1; |
以下操作失败:
1 | delete from view_user_course where id=3; |
其它
视图中的查询语句性能要调到最优;
修改操作时要小心,不经意间你已经修改了基本表里的多条数据;
在mac上通过Homebrew安装redis
安装命令
1 | brew install redis |
安装完成后提示
1 | To have launchd start redis now and restart at login: |
执行提示
1 | brew services start redis |
完成后提示
1 | Cloning into '/usr/local/Homebrew/Library/Taps/homebrew/homebrew-services'... |
ok~redis 已经启动
mac下安装python
知乎上说,不要在mac自带的python里折腾,怕折腾蹦了影响系统
用brew 安装,且自带pip
安装python2 & python3
1 | brew install python |
1 | brew install python3 |
1 | This formula installs a python2 executable to /usr/local/bin. |
设置PATH
vim ~/.zshrc 加入export PATH="/usr/local/opt/python/libexec/bin:$PATH"
验证PATH设置成功
输入which python
如果显示 /usr/local/opt/python/libexec/bin/python则说明成功
如何使用系统的python
如果有需要想使用一下系统的Python,输入/usr/bin/python即可
python之禅
虽然python不是我的入门语言,之前一直抵触它的缩进语法,但通过《python宝典》的入门学习,发现python成为当前最热门的语言不是偶然。
python社区和语言一起成长,融合了多种语言的特性及优点。
刚试着用import this 查看了python之禅
1 | The Zen of Python, by Tim Peters |
1 | python之禅 by Tim Peters |
上升到开发哲学上,任何语言都是适用的
为xxx感到荣幸
xxx—–代表一切可以感恩和赞颂的“人”或“事”或“自己”
某天,我发现自己一直以来都很少去感恩别人,包括自己所取得的一些小成就,也是被自己所否定不认可,总觉得自己(或别人)做的还是不够好,不够完美。可完美的事情真得存在吗?
感恩自己身边的人和事,才会发现生活原来是如此的美。自然的美,和谐的美,错误的美,成功的美……
想象着,自己和父母都存在如此的心声,那将是多么幸福的事:
有这样的儿子感到荣幸
有这样的老婆感到荣幸
有这样的公司感到荣幸
有经历这样的项目感到荣幸
为我的抉择感到荣幸
……
从今天起,试着去感恩吧!
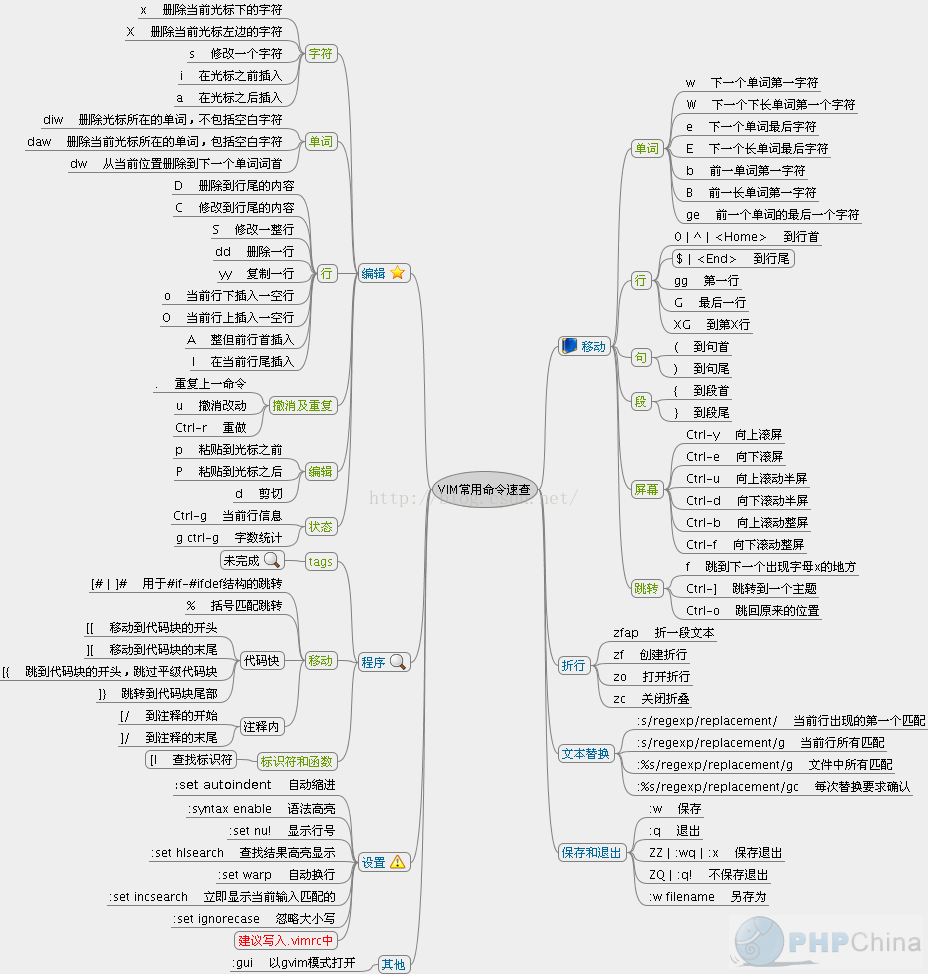
vim常用命令
插入
| 快捷键 | 说明 | 常用指数(自己) |
|---|---|---|
| a | 在当前光标后插入文本 | ★★★★ |
| A | 在本行行尾插入文本 | ★★★★★★ |
| i | 在光标前插入文本 | ★★★★★ |
| I | 在本行行首插入文本 | ★★ |
| o | 在光标下插入新行 | ★★ |
| O | 在光标上插入新行 | ★★ |
| h | 左移一个字符 | ★ |
| j | 下移一个字符 | ★ |
| k | 上移一个字符 | ★ |
| l | 右移一个字符 | ★ |
| $ | 移动至当前行的行尾 | ★★★★ |
| 0(数字零) | 移动至当前行的行首 | ★★★★★★ |
| H | 移动屏幕上端 | ★★★★★ |
| M | 移动屏幕中央 | ★★ |
| L | 移动屏幕下端 | ★★★★★ |
| gg | 到整个文件的第一行 | ★★★★★★★ |
| G | 到整个文件的最后一行 | ★★★★★★★★ |
| nG | 到第n行,如5G到第5行 | ★★★ |
| :n | 到第n行 | ★★★★★★★★ |
删除和取消
| 快捷键 | 说明 | 常用指数(自己) |
|---|---|---|
| x | 删除光标所在处字符 | ★★★★★ |
| nx | 删除光标所在处n个字符 | ★ |
| dd | 删除光标所在行(+p剪切) | ★★★★★★★ |
| ndd | 删除n行(+p剪切) | ★★ |
| dG | 删除光标所在行值末尾 | ★★★★ |
| D | 删除光标所在处至行尾 | ★★★★ |
| :n1,n2d | 删除指定范围的行 | ★★★ |
| u | 取消上一步操作 | ★★★★★★★★★ |
复制和粘贴
| 快捷键 | 说明 | 常用指数(自己) |
|---|---|---|
| yy,Y | 复制当前行 | ★★★★★ |
| nyy,nY | 复制当前行以下的n行 | ★★★ |
| p | 将内容粘贴所在行的下一行 | ★★★★★★★ |
| P | 将内容粘贴所在行的上一行 | ★ |
搜索替换
| 快捷键 | 说明 | 常用指数(自己) |
|---|---|---|
| /string | 查找string(+n下一个) | ★★★★★ |
| :%s/old/new/g | 全文替换,如:%s/123/789/g | ★★★ |
屏幕
| 快捷键 | 说明 | 常用指数(自己) |
|---|---|---|
| ctrl+u | 向上滚动半屏 | ★★★★★ |
| ctrl+d | 向下滚动半屏 | ★★★★★ |
| ctrl+b | 向上滚动整屏 | ★★★★★ |
| ctrl+f | 向下滚动整屏 | ★★★★★ |
归纳图片